第二章 指令系统
数据表示,数据类型
采用标识符数据表示的优点?(三简化,硬件(一致性检查,数据类型转换),软件,数据库)缺点?(三个,数据,指令,硬件)
标识符数据表示与数据描述符描述的差别?
浮点数表示rm增大,带来的影响(6个);
尾数下溢的处理方法(4种),各自的优缺点
编址方式(4种),==对齐方式==,大小端;高位/低位交叉编址;寻址方式(四种)
定位方式(3),各自的含义,为什么要定位(4)
操作码设计(3种),信息冗余度计算
RISC基本思想(定义/目的),RISC特点(指令(4),硬,优化编译)
RISC关键技术(延时转移,指令取消,寄存器窗口重叠,指令流调整技术,高速缓冲寄存器Cache,优化设计编译系统;)
数据表示与数据类型的定义和区别
数据表示
是指计算机硬件能够直接识别,可以被指令系统直接调用的那些数据类型。
数据结构
反映了应用中要用到的各种数据元素或信息单位之间的结构关系。数据结构要通过软件映像,变换成机器所具有的数据表示来实现。不同的数据表示可为数据结构的实现提供不同的支持。
数据类型
确定哪些数据类型用数据表示来实现的原则
缩短程序的运行时间
减少CPU与主存储器之间的通信量
这种数据表示的通用性和利用率
标志符数据表示,数据描述符
标志符数据表示
一般的计算机中,数据存储单元(寄存器、主存储器、外存储器等)只存放纯数据,数据的属性通过指令中的操作码来解释:数据的类型,进位制,数据字长,寻址方式,数据的功能;
这使得同一种操作(例如加法)通常有很多条指令。
对应改进:
添加类型标志位/标志符,用来描述对应数据的属性。这个标志符由编译器或者其他系统软件建立,对程序员透明。这会使得数据的存储量增加,指令的存储量减少。
==采用标志符数据表示方法的优点:==
简化了指令系统。
由硬件实现一致性检查和数据类型转换。
简化程序设计,缩小了人与计算机之间的语义差距。
简化编译器,使高级语言与机器语言之间的语义差距大大缩短。
支持数据库系统,一个软件不加修改就可适用于多种数据类型。
方便软件调试,在每个数据中都有陷井位。
==主要缺点:==
数据和指令的长度可能不一致
可以通过精心设计指令系统来解决。
指令的执行速度降低
但是,程序的运行时间是由设计时间、编译时间和调试时间共同组成的。
采用标志符数据表示方法,程序的设计时间、编译时间和调试时间可以缩短。
硬件复杂度增加
由硬件实现一致性检查和数据类型的转换。
数据描述符
对于一列数据进行相同的操作,它们具有共同的特征或者说标志。
- 定义:为进一步减少标志符所占用的存储空间,对向量、数据、记录等数据,由于元素属性相同,采用数据描述符。
区别
标志符只作用于一个数据,而数据描述符要作用于一组数据。
==浮点数的表示方法==
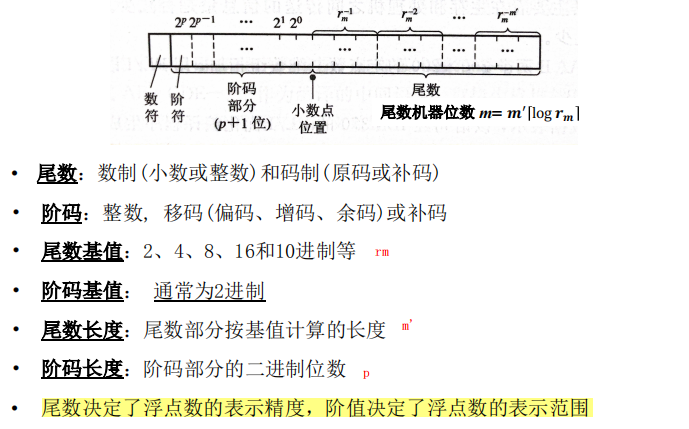

变化特征
随着$r_m$的增大,可以表示的最小值减小,可以表示的最大值增大,也就是
- 可以表示的数的范围增大了。
- 可以表示的数的个数增大了。
- 在$r_m=2$的浮点数相重叠的范围内,数的密度分布越稀疏
- 表示的数据精度下降
- 运算中的精度损失减小(因为对阶移位的机会和次数减少,书的表示范围扩大,导致尾数溢出的右规机会减少)
- 运算速度提高(理由同上,由于减少了右规次数,而提高了运算速度)

尾数下溢的处理方法
注意每种方法的误差计算
截断法,直接抛弃
优点:实现简单,不需要增加硬件,不需要处理时间。
缺点:误差较大,无法调节
舍入法,四舍五入
在机器运算的规定字长之外增设一位附加位,存放溢出部分的最高位,每当进行尾数下溢处理时,将附加位加1。
优点:实现简单,增加硬件少,最大误差小,平均误差为0.
缺点:处理速度慢,需要花费在附加位上加1以及因此产生的进位时间。
恒置“1”法
将有效字长的最低一个位置,设置为$r_m/2$
优点:实现简单,不需要增加硬件和处理时间,平均误差接近0
缺点:最大误差比较大
查表舍入法
用ROM或者PLA存放下溢处理表。
优点:速度快,平均误差可以调节到0
缺点:硬件量大
基本的编址方式,寻址方式和定位方式
编址方式
常见的有位编址,字节编址,字编址,块编址
字节编址,字访问
按照每个字节都有一个地址,但是访问的时候一次访问一个字。
优点:有利于符号处理
缺点:
- 地址信息浪费(32位机,每个字对应4个字节,也就是最后2位被浪费;64位机,每个字对应8个字节,最后3位被浪费
- 存储器空间浪费
- 读写逻辑复杂
- 大端小端问题
==数据对齐访问:==
从任意位置都可访问
优点:节省存储资源
缺点:地址信息浪费,降低了读写速度,读写控制逻辑复杂
从一个存储字的起始位置开始访问
优点:读写速度快,控制逻辑简单
缺点:地址信息浪费,存储资源浪费
从地址的整倍数位置开始访问
优点:速度快,无论哪种访问都可以在一个周期内完成
缺点:一定程度上浪费了存储器资源,控制逻辑仍然比较复杂
大小端问题
地址存储时一定是从低位地址递增向高位地址存储。
- 大端(高尾端):数据的高位字节存储到低地址,例如(12 | 34 | 56 | 78 ),地址从左到右递增
- 小端(低尾端):数据的高位字节存储到高位地址,例如(78 | 56 | 34 | 12)地址从左到右递增
编址之独立编址:零地址空间的个数
通用寄存器,主存,输入输出设备
- 三个零地址空间:各自独立编址
- 两个:主存+输入输出,通用寄存器
- 一个:最低端是通用寄存器,高端是输入输出设备,中间主存
- 隐含编址:Cache与堆栈
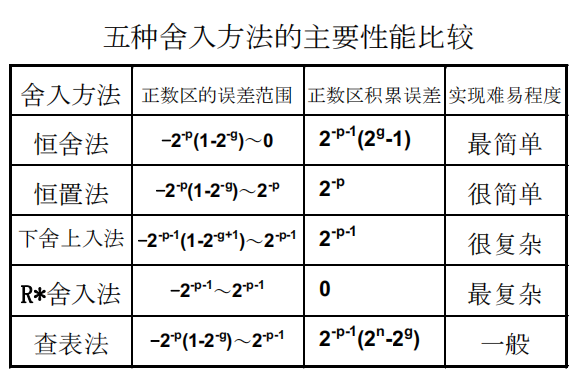
交叉编制:高位交叉N/低位交叉Z
给定(i,j),其中i从0开始,j从0开始,求其所处线性位置;
给定线性位置,求其对应二维位置;
低位交叉编址(通过低位来区分存储体,因为同一个存储体内的低位都是相同的)
提高读写的速度
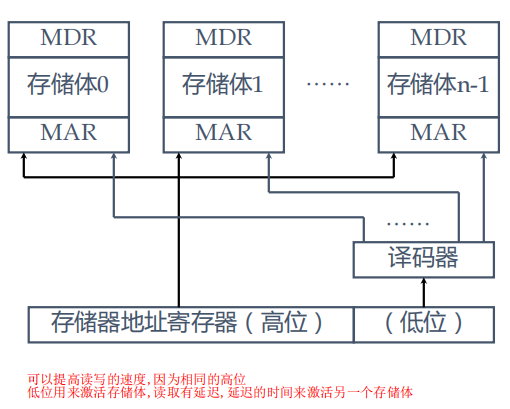
高位交叉编制(高位来区分存储体,一个存储体填满之后再去填写另一个存储体)
优点:适用于共享存储器的多机系统,适用于指令和数据分别存储在不同的分体中,有利于存储器的扩充
缺点:性能比低位交叉编制差
寻址方式
- 立即数寻址
- 寄存器寻址(操作数来自寄存器,结果写回寄存器)
- 面向主存的寻址
- 直接寻址
- 间接寻址
- 变址寻址(相对寻址,基址寻址)
- 面向堆栈的寻址(隐含的,指令中不需要给出操作数地址)
定位方式
定义:研究程序的主存物理地址什么时候确定,采用什么方式实现(也就是逻辑地址和物理地址的转换)
程序为啥需要定位?
- 程序的独立性
- 程序的模块化
- 数据结构运行过程中大小变化
- 有些程序本身太大
直接定位
在程序装入主存储器之前,程序中的指令和数据的主存物理就已经确定了。(一次装入一整个程序,整个系统的地址完全为该程序服务)。
静态定位
在程序装入主存储器的过程中随即进行地址变换,确定指令和数据的主存物理地址。
动态定位
在程序执行过程中,当访问到相应的指令或数据时才进行地址变换,确定指令和数据的主存物理地址。
对应需要增加基址寄存器和地址加法器硬件。基址寄存器存储装入程序的起始地址,加法器硬件将基址寄存器内容与逻辑地址相加,形成物理地址。可在指令中加入相应的标志位来指明指令地址是否需要加基址。
操作码优化设计(也就是减少指令长度)
指令系统优化设计的主要目标是:节省程序的存储空间,指令格式尽量规整,便于译码
对于指令所占内存大小来说,固定长度> 扩展编码> Huffman编码
==信息冗余量的计算:==
$R=\frac{当前长度-最短平均长度}{当前长度}$
固定长操作码
优点:规整,译码简单
缺点:浪费信息量(操作码总长位数增加)
Huffman编码
对发生概率最高的事件用最短的位数(时间)来表示(处理),而对出现概率较低的事件允许使用较长的位数(时间)来表示(处理),使表示(处理)的平均位数(时间)缩短
操作码的==最短平均长度==通过公式计算:其中pi代表第i种操作码在程序中出现的概率。
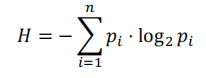
优点:信息冗余量小
缺点:长度不规整,译码困难;与地址码共同组成固定长的指令比较困难。
扩展编码
长度不是定长,但是只有有限几种码长。仍采用高概率指令短码,低概率指令长码。
4-8-12等长扩展编码法
等长15/15/15扩展法
等长8/64/512
每增加4位,都对应只使用这4位的0000-0111,共计8种。留下8种给后面用。
附带内容:指令字格式的优化
- 扩展编码;2. 多种寻址方式以缩短地址码长度;3. 采用多种地址制;4. 在同种地址制内采用多种地址形式;5. 使用多种不同的指令字长度
RISC 的基本原理和思想、实现的关键技术
RISC基本思想:通过减少指令种类和简化指令功能来降低硬件设计的复杂度,提高指令执行速度
RISC定义与特点:
- 减少指令和寻址方式种类:指令系统只选择高频指令,减少指令数量,一般不超过100条;减少寻址方式,一般不超过两种
- 固定指令格式:指令格式限制在两种以内,并使全部指令都在相同的长度
- 大多数指令在一个时钟周期内完成
- 采用LOAD/STORE结构:扩大通用寄存器数量(一般不少于32个),尽量减少访存,只有L/S可以访存,其他只对寄存器操作
- 硬布线逻辑:大多指令采用硬布线逻辑,少数微程序
- 优化编译:通过精减指令和优化设计编译程序,简单有效地支持高级语言实现
RISC思想精华:减少CPI
关键技术
延时转移,指令取消,寄存器窗口重叠,指令流调整技术,高速缓冲寄存器Cache,优化设计编译系统;
延时转移技术:为了流水线不断流,在转移指令后插入一条没有数据相关和控制相关的有效指令,儿转移指令被延迟执行;这一过程由编译器负责。
限制条件:被移动指令与经过的指令无数据相关;被移动指令不破坏条件码;
指令取消技术:分两种情况,向后转移(循环程序)+向前转移(条件指令)
向后转移:循环体第一条指令安放在两个位置:循环体之前与循环体条件判断之后。转移成功不取消。(因为循环,希望其转移成功)
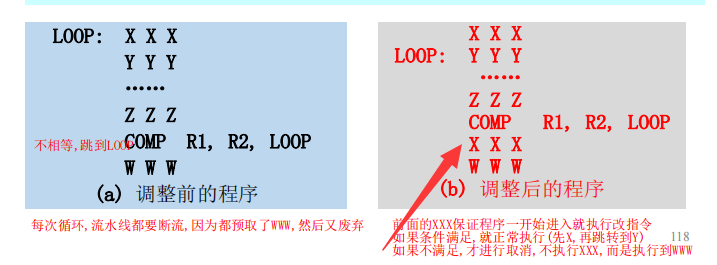
向前转移:转移成功则取消。(因为执行的是不成功的指令)
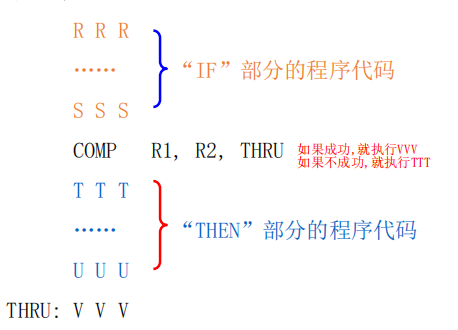
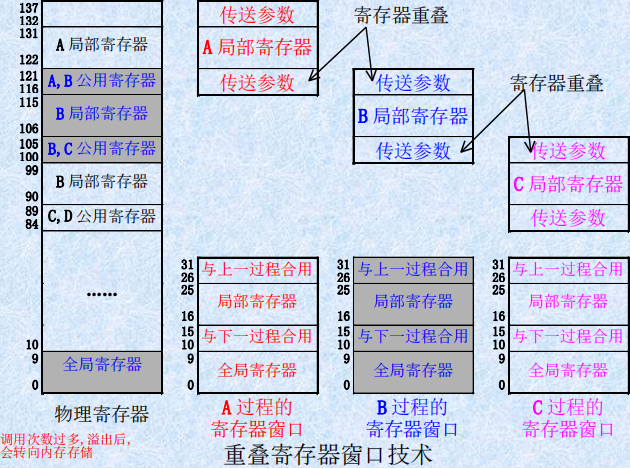
重叠寄存器窗口技术:设置一个数量比较大的寄存器堆,并把它划分成很多个窗口。 在每个过程使用的几个窗口中:
- 有一个窗口是与前一个过程共用
- 有个窗口是与下一个过程共用
指令流调整技术:通过变量重新命名消除数据相关,提高流水线效率
采用高速缓冲寄存器Cache:指令Cache和数据Cache
优化设计编译系统:寄存器优化,指令序列调整,子程序库
第三章 存储系统
存储系统的定义?(组织成一个)
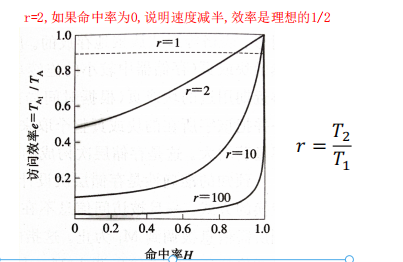
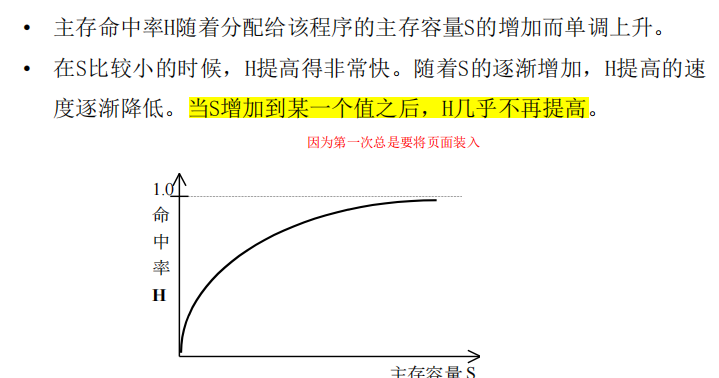
命中率H如何计算?访问周期T和命中率的关系(一路飙升)? 存储系统访问效率e?
啥是并行存储器?有什么显著缺点(4).
交叉访问存储器的加速比N的计算(与转移概率g相关)?两种交叉访问的目的?
虚拟存储器的三种方式的各自的优缺点?
加快内部地址变换的方法?(多级页表,目录表,快慢表,散列函数),如何计算一个给定虚拟地址空间,页面大小和页表项大小的系统需要的多级页表层级数?
如何评价页面替换算法?(命中率,实现难度)有几种?(4),各自的描述?
主存命中率的影响因素有啥?(存,页,调度)各自如何影响的?
与Cache相关的,三种地址映像的绘图?如何计算?Cache的一致性问题出现的情况?(两种),处理方式,各自的优缺点?(简,可靠,通信次数,硬件)
Cache的预取算法?三种各自的描述?
存储系统定义和评价标准(价格、容量和速度)
命中率的计算H,访问周期与命中率的关系T,存储系统的访问效率e
并行存储器的加速比N=平均有效字的期望
组成存储系统的关键:将速度,容量,价格不同的多个物理存储器组织成一个存储器,其速度最快,容量最大,单位容量价格最便宜。
存储系统的定义
两个或两个以上速度、容量和价格各不相同的存储器用硬件、软件、或软件与硬件相结合的方法连接起来成为一个存储系统。这个存储系统对程序员透明,并且该存储器速度接近速度最快的那个存储器,存储容量与容量最大的那个存储器相等,单位容量的价格接近最便宜的那个存储器。
一般计算机系统有两种存储系统:Cache存储系统(Cache与主存)和虚拟存储系统(主存与外存)。前者目的是加快存储器速度,后者为了扩大存储器容量。
评价标准
容量:要求提供尽量大的地址空间,可以随机访问
- 只对系统中存储容量大的编址,其他存储器内部编制/不编址(如Cache)
- 设计容量很大的逻辑空间,将相关存储器都映射到这个大空间(虚拟存储系统)
价格:
计算公式:

速度:访问周期/存取周期/存储周期/存取时间/命中率
在一轮存储器访问过程中,命中率在M1存储器访问到的概率

访问周期与命中率的关系
$$
T=H \cdot T_1+(1-H)\cdot T_2
$$
当命中率趋近于1,T趋近于T1存储系统的访问效率(与命中率和两级存储器的速度之比有关系)

关系图:
- 当r过大时,前期提高命中率对整个存储系统的效率提升不大
- 提高存储系统访问效率的方法:提高命中率H,两个存储器的速度相差不要太大。
存储系统的层次结构
多层次寄存器:寄存器堆,先行缓冲站,高速缓冲存储器Cache,主存,联机存储器,脱机存储器
并行存储器
指的是将原本m字w位的存储器改变成为m/n字n*w位的存储器。
逻辑上来看,就是指将地址码分为两个部分,一部分负责存储存储器的地址,另一部分选择数据。
缺点:
- 取指令冲突:遇到转移指令且转移成功时,一个存储周期内读到的n条指令,后面的几条将无用
- 读操作数冲突:一次性读出n个,不一定都有用
- 写数据冲突:需要凑齐n个数据之后才一起写入存储器(如果只写一个,需要读入n个,修改一个,写回n个)
- 读写冲突:要读入的字和要写入的字同在一个存储器内,无法在一个存储周期完成
交叉访问存储器
高位交叉访问存储器(使用高位区分存储体)
目的:扩大存储器容量
低位交叉访问存储器(使用低位区分存储体)
目的:提高存储器访问速度
为了提高速度,通过n个存储体分时启动,近似实现并行存储的读写操作。
并行存储器的加速比N的计算
N也是每个存储周期能够访问到的平均有效字的个数
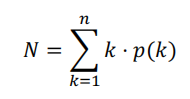
假设转移概率为g:存储体越多,转移概率越小,加速比越大!
但是随着存储体个数不断增大,存储体个数对有效字长的影响会逐渐减小,例如g=0.2,每五条出现一条转移,即便提高存储体个数,前五个也应当会出现一个转移指令,那么后面的指令冗余
虚拟存储器工作原理(页,段,段页式)
地址组成:
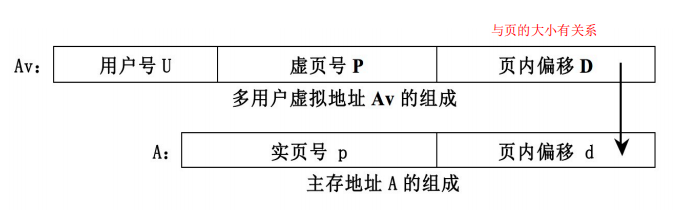
多用户虚拟地址Av变换成主存实地址A
多用户虚拟地址中的页内偏移D直接作为主存实地址中的页内偏移d
主存实页号p与它的页内偏移d直接拼接起来就得到主存实地址A。
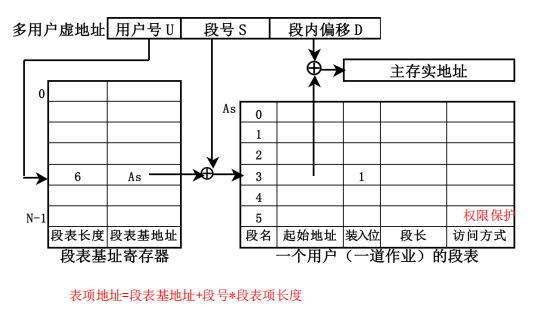
段式虚拟存储器
地址映像:每个程序段都从0地址开始编址,长度可长可短,可以在程序执行过程中动态改变程序段的长度。
地址变换方法:由用户号找到基址寄存器,读出段表起始地址,与虚地址中段号相加得到段表地址,把段表中的起始地址与段内偏移D相加就能得到主存实地址。
==优点:==
程序的模块化性能好。
便于程序和数据的共享。
程序的动态链接和调度比较容易。
便于实现信息保护。
==缺点==
- 地址变换所花费的时间长,两次加法(先找到该用户的段表,找到后做一次加法得到段的起始地址,再做一次加法得到对应段内的具体位置)
- 主存储器的利用率往往比较低。
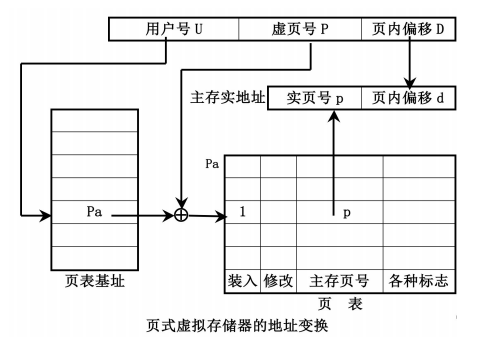
页式虚拟存储器
地址映像:虚拟地址空间划分为大小固定的页,把主存的地址空间同样划分为大小相等的固定大小的页。
优点:
- 主存储器的利用率比较高
页表相对比较简单
地址变换的速度比较快(只需要做一次加法)
对磁盘的管理比较容易
缺点:
程序的模块化性能不好
页表很长,需要占用很大的存储空间
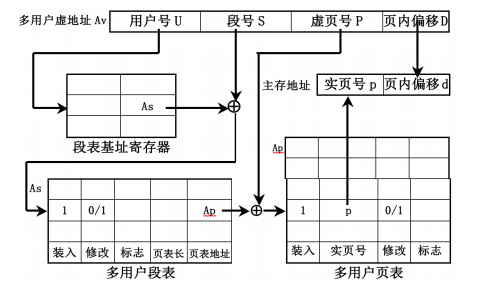
段页式
- 地址映象方法:每个程序段在段表中占一行,在段表中给出页表长度和页表的起始地址,页表中给出每一页在主存储器中的实页号
- 地址变换方法:先查段表,得到页表起始地址和页表长度,再查页表找到要访问的主存实页号,把实页号p与页内偏移d拼接得到主存实地址。
加快内部地址变换的方法
- 导致虚拟存储器速度降低的主要原因
- 页表或者段表过大,查找需要花费很多时间
- 页表或者段表在内存中的存放不连续,无法通过偏移量查找对应地址
解决方法:多级页表
页表级数的计算公式:需要多少个页面(log转换为比特位)/一个页面能够存储多少页表项(log转换为bit位)
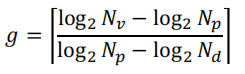
内存中必须保留一级页表,把调入到内存中的程序的相关页表保留在内存中,其他存储在磁盘中即可。但由此产生问题:访问内存的次数增加,需要加快查表速度。
目录表法
压缩页表的存储容量,用一个容量比较小的高速存储器来存放页表,从而加快页表的查表速度。
缺点:随着主存容量增大,目录表的容量同样增大,可扩展性较差。且造价高,查表速度降低。
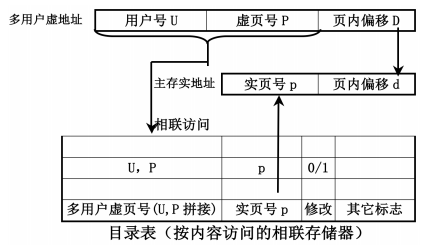
快慢表
目录表为快表(硬件实现),完整表页为慢表(可能是多级页表),快表大小压缩,并不需要匹配整个内存,只需要8-16个存储字,内存转换速度非常快
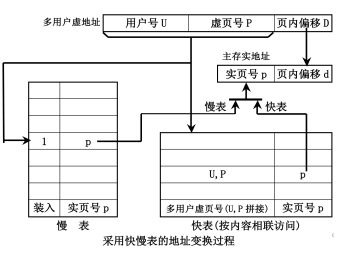
散列函数
把按内容的相联访问变为按地址访问,从而支持更大的快表。
散列部件的输入是用户号+虚拟页号,输出是映射完成的快表的地址。
优点:速度快,可扩展性强
缺点:需要额外的硬件
页面替换算法
评价算法的指标:
- 命中率
- 算法是否容易实现
页面替换使用场合:
虚拟存储器中,主存页面的替换,一般用软件实现。
Cache中的块替换,一般用硬件实现。
虚拟存储器的快慢表中,快表存储字的替换,用硬件实现。
虚拟存储器中,用户基地址寄存器的替换,用硬件实现。
在有些虚拟存储器中,目录表的替换。
随机替换算法
优点:算法简单,容易实现
缺点:没有利用历史信息,没有反映程序的局部性,命中率低
最优替换算法:理想算法,仅用作评价其它页面替换算法好坏的标准。
近期最少用算法LRU:选择近期最少访问的页
优点: 能够比较正确反映程序的局部性,把最久未被访问的页作为被替换页
先进先出算法FIFO:选择最早装入主存的页作为被替换的页
优点:容易实现,利用了历史信息但是没有利用局部性。
主存命中率影响
页面大小
当页面大小为某个值,结果存在最值。

页面大小导致的其他结果:
- 页面增大:命中率可能下降(当d>Sp),造成的空间浪费可能增大,内存空间利用率下降。可用页面减少。
- 页面减小:命中率可能下降(d<Sp),页表和页面表在内存中占的比例将会增大。
主存容量
页面调度
请求式:当使用到的时候,再调入主存
预取式:在程序重新开始运行之前,把上次停止运行前一段时间内用到的页面先调入到主存储器,然后才开始运行程序。其主要优点是可以避免在程序开始运行时,频繁发生页面失效的情况;
其主要缺点:如果调入的页面用不上,浪费了调入的时间,占用了主存的资源。
Cache存储系统基本工作原理
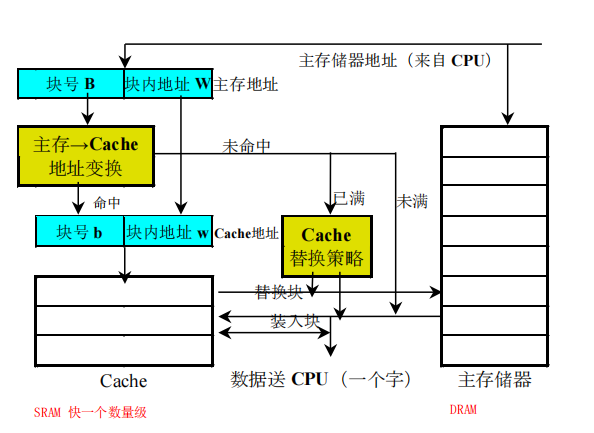
地址映像
直接映像
主存储器中一块只能映象到Cache的一个特定的块中,通常是对Cache的块数进行取模。因此,Cache地址与主存储器地址的低位部分完全相同。
用主存地址中的块号B去访问区号存储器,把读出来的区号与主存地址中的区号E进行比较。只有比较相等并且有效位为1,才访问Cache,获得块内内容。为了提高Cache速度,可以将区号存储器和Cache合并成一个存储器。
优点:硬件简单,不需要相联访问存储器;访问速度快实际上不需要进行地址变换。
缺点:块的冲突率比较高。


全相联
主存中的任意一块到Cache中的任意一块。
优点:块冲突概率低,空间利用率高。
缺点:相联存储器成本高,查表速度慢。

组相联
主存和Cache划分为大小相同的块和组。组间直接映射,组内全相联映射。
优点:冲突率较低,块的利用率大幅度提高,块的失效率明显降低。
缺点:实现难度和造价比较高。


Cache的一致性问题
造成Cache与主存内容不一致的原因:
由于CPU写Cache,没有立即写主存(Cache新)
由于IO处理机或IO设备写主存(主存新)
Cache的更新算法:
写直达法through,写入Cache时也写入主存
可靠,实现简单,但是与主存 通信太多(每次写写一个字),要设置后行写数缓冲站(一个高速寄存器堆)
写回法back,数据只写入Cache,仅当替换时才把修改过的Cache写回内存
不如写直达可靠,并且控制复杂,但是通信少,每次写一个块,不需要写数缓冲站
写Cache的两种方法:
- 不按写分配法:写Cache不命中,只需要把写的字写入内存(写直达)
- 按写分配法:不命中,还要把一个块从主存读入Cache(写回法)
Cache的预取算法
按需取。当出现Cache不命中时,才把需要的一个块取到Cache中。
恒预取。无论Cache是否命中,都把下一块取到Cache中。
不命中预取。当出现Cache不命中,把本块和下一块都取到Cache中。
主要考虑命中率是否提高,采用恒预取,不命中率降低很多75-85
不命中预取也能降低30-40