[TOC]
Crawler
1. 准备工作 查看对应的url.
发送请求路径后,返回的是一个html网页得源代码,将信息从网页源代码中提取出来.
对于网页资源得请求是持续得,而不是一下子就能够返回整个网页得.
使用谷歌浏览器,在控制台界面选择NetWork,选择时间轴上的信息,然后点击Name中选定的内容,出现的Headers就是我们发送给服务器的内容.具体服务器发送给本地的内容存在于Headers旁边的Response模块.
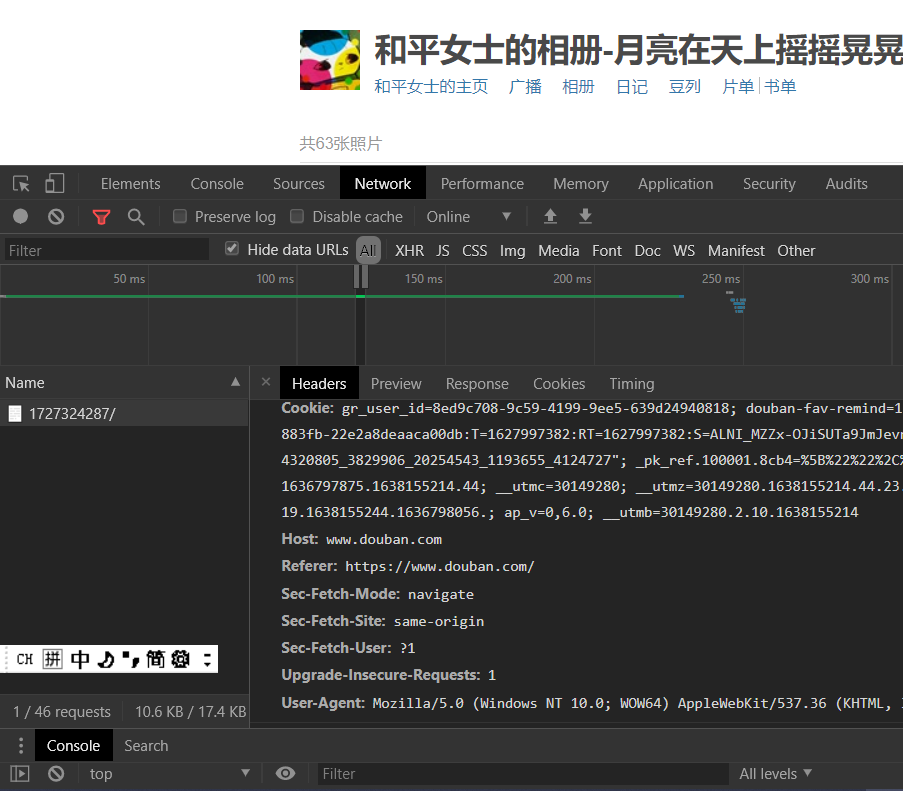
其中的Headers中的内容,拉到最后,有一个User-Agent指代用户代理,也就是浏览器版本内容等等.
- 表明当前浏览器可接受的界面类型对应的浏览器版本.例如上图中的
Mozilla指代当前谷歌浏览器可以接受适配于Mozila浏览器的内容. - 还可以表明当前计算机相关的内容,例如
Windows NT 10.0代表当前使用的是Win10操作系统,64位版本. Cookie:想要爬取登录后才能查看的内容,必须先设置操作好Cookie.
2. 层级结构
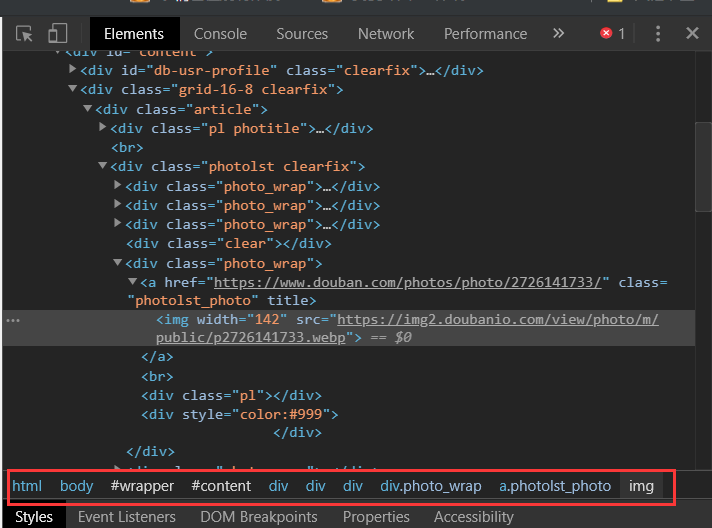
根据控制台界面上特定元素的定位信息,来确定要爬取内容的层级结构.
3. 编码规范
1 | # coding=utf-8 |
Python文件中可以加入main函数用于测试程序:
用来定义程序的入口地址或者说程序开始运行的第一个函数位置.相对更加清楚地看到程序地流程.
1 | if __name__ == "__main__": |
引入外部库
引入本地生成的函数文件.
应当是从文件夹中引入文件.例如下图中,从文件夹
test1中引入文件t1.使用文件中的函数直接通过
.运算符计科完成.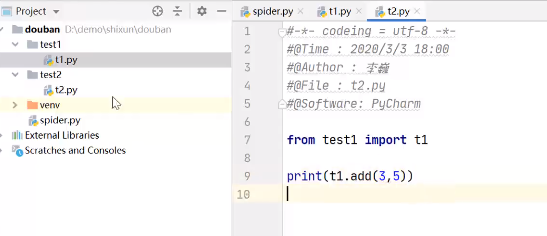
常用的是引入外部模块
1
2
3
4
5import bs4 # 网页解析获取数据
import re # 正则表达式,文字匹配
import urllib.request,urllib.error # 指定url,获取网络数据
import xlwt # 进行excel操作
import sqlite3 # 进行SQLite 数据库操作
4. 整体流程
爬取网页
解析数据
数据解析通常是逐一解析数据,与爬取网页通常是共同存在的,同步地
保存数据
5. 爬虫伪装
发送请求时对对象封装.
通常选择将发送Request对象中的headers设置为浏览器的样式.
6. 函数详解
askURL(url)返回单个
url的页面内容.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19# 爬取指定一个url的网页信息
def askURL(url, method = "GET"):
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 "
"Safari/537.36",
}
req = urllib.request.Request(url = url, headers = header, method = method)
html = ""
try:
responce = urllib.request.urlopen(req)
html = responce.read().decode('utf-8')
except urllib.error.URLError as e:
# 判断是否含有属性`code`,也就是查看返回的错误信息是否是有代码例如`404`
if hasattr(e, "code"):
print(e, "code")
if hasattr(e, "reason"):
print(e, "reason")
return html返回的相当于是字符串.
该函数需要调用25次,来爬取25个范围.
getData(baseurl)给定基本的
url,例如本实验中是"https://movie.douban.com/top250?start=",每次增加都只需要更改start的内容.通过循环,爬取多个页面,每次都对爬取到的页面内容进行解码解析,将需要的内容存放在容器中,然后返回这个容器.
1
2
3
4
5
6
7
8# 首先是爬取每一个网页的内容
# 因为时循环爬取,所以这里仅给定循环中的内容
for i in range(10):
url=baseurl+str(i*25)
# 获取url对应内容
pagecontent=askurl(url)
# 对内容进行解析
soup=BeautifulSoup(pagecontentm"html.parser")此时获取到的是
soup,可以对内容进行解析筛选,得到我们想要的数据了.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31# 筛选内容
# 首先将所有要找的信息所在的大框架找到
# 例如本实例中,找到的信息都存在于<div class="item">中
for item in soup.find_all('div', class_ = "item"):
data = [] # 一部电影的所有信息
item = str(item)
# 然后通过创建正则匹配模式,对想要的内容进行匹配
link = re.findall(findLink, item)[0] # 此时找到的就是电影的详情页链接
imgSrc = re.findall(findImgSrc, item)[0]
name = re.findall(findName, item)[0]
otherName = re.findall(findOtherName, item)[0].replace('\xa0', '')
rating = re.findall(findRating, item)[0]
cnt = re.findall(findCnt, item)[0]
info = re.findall(findInfo, item)[0].strip().replace('\xa0','')
quote = re.findall(findQuote, item)
if len(quote) == 0:
quote = ""
else:
quote = quote[0]
data.extend([link, imgSrc, name, otherName, rating, cnt, info, quote])
# 创造正则匹配表达,用来确定链接的位置
findLink = re.compile(r'<a href="(.*?)">')
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S) # re.S,匹配模式,包含换行符
findName = re.compile(r'<span class="title">(.*?)</span>')
findOtherName = re.compile(r'<span class="other">(.*?)</span>')
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*?)</span>')
findCnt = re.compile(r'<span>(\d*)人评价</span>')
findQuote = re.compile(r'<span class="inq">(.*)</span>')
findInfo = re.compile(r'<p class="">.*<br/>(.*?)</p>', re.S)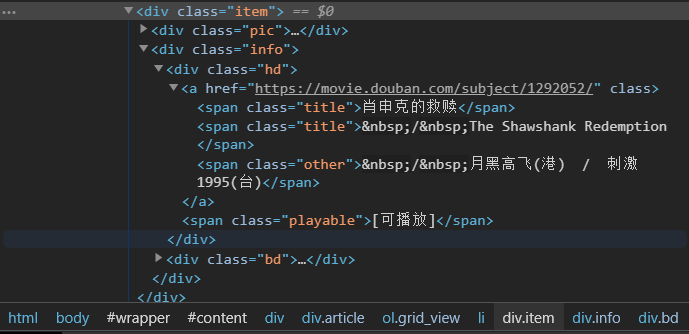
关于用到的库
整体库
1 | from bs4 import BeautifulSoup # 网页解析获取数据 |
urllib
urllib的作用是向另一端的服务器发送一个request,然后得到一个responce,这个收到的响应通常等价于上面提到的控制台中的Responce内容.
一般用法
1
2
3
4# 使用一个get的方式直接获得一个网址
baseurl="http://www.baidu.com"
responce=urllib.request().openurl(baseurl)
temp=responce.read().decode('utf-8')最好是先解码(decode,decode会将原本的杂乱信息解码成一个比较规矩的信息)
1
2
3
4
5
6# 通过post方式发送请求获得响应
# 使用网站 httpbin.org
# 需要先提前引入 urllib.parse库
data = bytes(urllib.parse.urlencode({"Hello": "world"}), encoding = "utf-8")
responce = urllib.request.urlopen("http://httpbin.org/post", data = data)
print(responce.read().decode('utf-8'))使用post 方式发送请求必须首先设置表单信息(二进制形式)
也就是信息的转换需要满足:
首先将内容通过编码,得到
utf-8格式的数据,然后通过bytes转换成二进制.信息->编码(通过
urllib.parse.urlencode(dict,encoding=),这里的encoding默认utf-8)->转换成二进制(通过bytes(info,encoding=),这里的encoding显示说明且与前面的一致)然后再调用
urllib.request.urlopen(baseurl,data=)通过这种方式访问网站得到的信息,并没有经过伪装,因为此时的服务器接收到的内容仍然会显示当前的用户代理为
Python-urllib/3.9而不是浏览器的信息.伪装方法:发送请求时伪装
request.headers(User-Agent=)超时控制
在
urllib.request.openurl(baseurl,timeout=)设置时间上限,如果请求时间超过这个上限而没有接收到应答,停止接受和请求,直接返回一个错误.
如果在此时间到达之前就返回了响应结果,则没有啥问题.
在设置爬虫时,需要准备好如何面对超时的问题.例如如果超时,就不去爬取对应的页面.
可以等到最后再针对性处理
请求头解析
对于返回的
responce,先不去直接read全部内容,而是直接选择性读取.例如读取状态码:
responce.status会输出获得到的返回状态码.使用
responce.getheaders()获得响应头信息,以列表形式返回.获得状态头中的特定部分的信息:例如获取服务器信息
responce.getheaders("Server")发送请求头:
1
2
3
4
5
6
7url = "http://www.baidu.com"
data = bytes(urllib.parse.urlencode({"USER": "ME"}), encoding = "utf-8")
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
req = urllib.request.Request(url = url, data = data, headers = header, method = "POST")
response其中的
headers中的用户代理信息来自与浏览器控制台一般发送请求信息时,如果要伪装成了浏览器,只需要将用户头信息中的
Agent改掉即可.在这里的实验中,尝试通过更改
header访问豆瓣,成功得到了所有的信息,然后将其进行解码并写入文件,可以得到最终的网页.注:
在得到网页时,想要将其写入一个文件,但是报错:

搜索解决办法后,发现传送门,然后进行了修改:
1
f = open("Douban.html", "w")
更改为
1
f = codecs.open("Douban.html", "w", encoding = "utf-8")
结果完全可行,将爬取到的内容全部写入了文件中.
bs4
bs4.BeautifulSoup按照选择的解析器,解析给定的二进制文件的内容.
例如当前有一个二进制文件
content使用时:
bs=BeautifulSoup(content,"html.parser")其中的
"html.parser"是指定解析器为解析html的内容.使用时返回的
bs是一个树形对象.例如要获取其中的title信息,则使用
bs.title,返回值为<title>豆瓣</title>如果不想要标签存在的话,增加一个
bs.title.string,返回豆瓣问题是,每次都只会返回找到的第一个给定类型的标签.
获取title信息
bs.title获取某标签的属性信息
bs.a.attrs返回的是字典类型,每一个名称对应一个键值,例如:
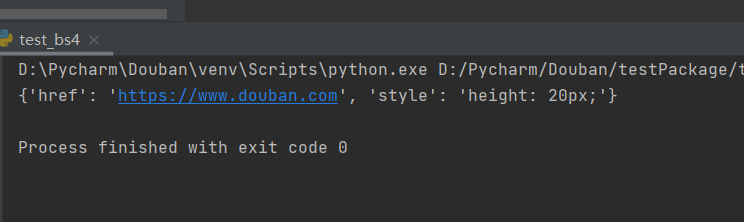
获得字符串
bs.title.string这里实际的返回值类型并不是字符串,而是其bs中的对象
注释类型
bs4.element.Comment自动去除注释的左右封闭标签,只保留文本内容.
与
bs4.element.NavigatableString的区别在于类型不同文档的遍历
传送门:
文档的搜索
定位想要的内容.
find_all的返回值通常是数组类型.find_all(index)字符串过滤,会查找与字符串完全匹配的内容
bs.find_all("a")search(正则表达式)实际上还是使用
find_all(re.compile("a"))相当于符合正则匹配的内容,例如含有
"a"方法搜索(传入函数,根据函数要求搜索)
例如查找所有含有
name属性的内容:1
2def name_is_exists(tag):
return tag.has_attr("name")使用如下:
1
bs.find_all(name_is_exists)
参数搜索
kwargs方法相当于传入参数,寻找指定参数的所有东西.
返回符合条件的标签及其子内容.
bs.find_all(id="head")例如查找含有
href的标签:bs.find_all(href=True)查找
text参数(文本参数)bs.find_all(text="hao123")返回的是
list也可以查找不止一个文本,即
text=["hao123","abc"]limit限制查找返回的个数bs.find_all("a",limit=6)返回查找到的前六个
a标签
选择器搜索
bs.select('')返回指仍然是列表的形式
也可以嵌套搜索,即查找
a标签中的类为name的标签,即需要bs.select("a[class='name']")以及
bs.select("head > title")相当于在树中确定根节点然后找子结点的操作
bs.select(".abc ~ .aaa")查找与
abc类同属兄弟节点的aaa类的内容.通过返回值t_list[0].get_text获取其中的文本信息.
常用的搜索方式
在爬虫中主要使用的搜索方式:
find_all("tag",属性="属性值")需要注意的是,Beatuiful为了避免属性中的
class与Python的关键字的class的重合,规定在使用属性中的class时写作class_,举例如下:1
2
3
4
5
6
7import bs4
import requests
url="..."
resp=requests.get(url)
page=BeautifulSoup(resp.text,"html.parse")
page.find_all("div",class_="title")返回的内容是标签内包含的所有内容.
find_all("tag",attrs={"属性":"属性值",[...]})通过这种方式,可以进一步定义到更加精确的多属性标签.
find_all()的返回值可以继续进行嵌套使用find_all()使用过程中应当注意其对应的返回值,正常情况下返回的结果是一个列表形式.
通过for循环进行遍历,进一步搜索和提取.
获取到想要的属性值和内容
- 如果想要获取到标签中的text,可以通过
.text获取. - 如果想要得到标签中的属性值例如
href,通过.get("href")获取
- 如果想要获取到标签中的text,可以通过
如果想要获取到兄弟标签,可以通过调用
element.next_sibling
re正则表达式
字符串模式.
建议在正则表达式中,被比较的字符串前面加上r 不用担心转义字符
常用参考传送门
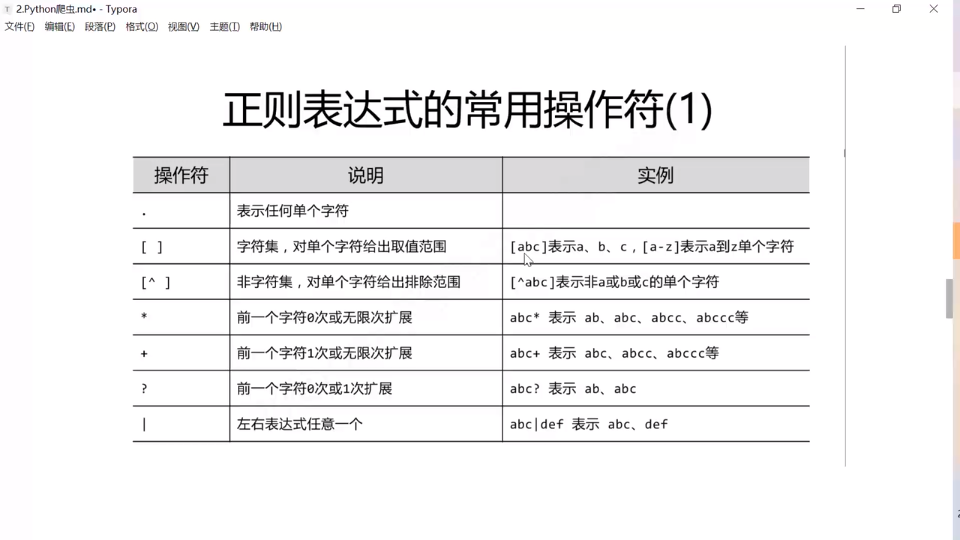
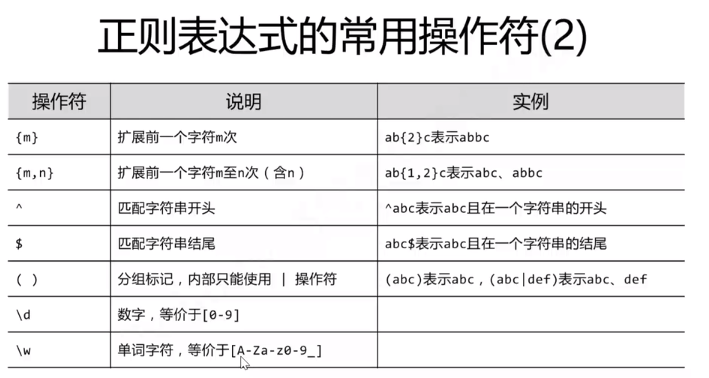
Re库主要功能:


常用功能:
re.compile(pattern)
预加载,相当于先编译一下匹配的pattern.
那么在后续的函数使用时,是使用该函数返回的obj进行match.
re.match()
通常只返回找到的第一个符合条件的位置,并且是从头开始匹配
先创造匹配模式(正则表达式),再对字符串进行匹配
1
2
3
4
5
6# 创造模式对象
pat = re.compile("AA") # 这里相当于创造正则表达式 让其他东西来匹配
m = pat.search("ADDCAA") # 返回值对象,其中的span代表位置 返回找到的第一个位置
print(m)
# 返回值:<re.Match object; span=(4, 6), match='AA'>不需要创造匹配模式,只应用于一个字符串
1
2
3
4
5
6# 如果不创建模式对象 相对简略
# 前面的是规则,是正则表达式
m = re.search("AA", "AsdaaAA")
print(m)
# 输出:<re.Match object; span=(5, 7), match='AA'>
re.findall()
返回所有符合条件的内容,返回形式为列表
举例
1
2
3
4# findall
# 找到所有的元素返回到列表中
print(re.findall("[A-Z]", "ThisisWords")) # 返回所有的大写字母
print(re.findall("[A-Z]+", "DOES this MatchING?")) # 返回所有至少有一个的大写字母簇
re.sub()
将给定的字符串中符合表达式的目标内容替换成给定的内容
1 | # sub |
re.finditer(pattern,string)
返回的是一个迭代器指针,通过for循环可以一次访问指针的内容,包括匹配结果字符串match和位置span
re.search(pattern,string)
返回的相当于是finditer函数返回的迭代器指针指向的内容,且是第一个.
这种东西称之为match对象,从match对象中拿数据,需要使用.group()方法,但返回的可能不是我们想要的,而是存在冗余信息.那么如果获取我们想要的特定内容,可以在想要获取的内容前面增加以下代码:
1 | (?P<varName>.*?) |
这样,匹配的内容将会被放在varName中,然后在使用时,可以通过.group("varName")进行获取.
例子:
re.S等状态位
可以在编译也就是预加载的时候进行处理,用来防止换行的出现
XPATH
是在XML文档中搜索内容的一门语言,相对简单,爬虫多用.
节点关系与树形结构类似.含有父结点,子结点,同胞节点的概念.
采用类文件夹路径的方式进行查找.
pip install lxml
进行内容获取时,通过调用其中的etree
例如:
1 | from lxml import etree |
其中除了可以应用于XML之外,还可以
- 直接指定
etree.HTML(text,parser,base_url)解析HTML - 指定
etree.parse(source,parser,base_url)解析文件
层级结构:
1 | result=tree.xpath("/book/author/nick/text()") |
通过text()进行内容的提取,只完全根据路径信息进行提取,返回的是一个列表list.
如果想要获取某个层级下的所有的后代节点,通过
1 | result=tree.xpath("/book/author//nick/text()") |
结果是找到author下的所有后代nick节点
如果想要进行层级的跳跃,例如我不关心儿子节点是什么,我只关心孙子节点,那么使用通配符*
举例:
1 | result=tree.xpath("/book/author/*/nick/text()") |
如果我只想要获取到的若干中间节点x中的第n个**(从1开始计数)**,那么可以写作:
1 | result=tree.xpath("/a/b/.../x[n]/...") |
如果想要获取到中间节点x的某个属性值attr为value的中间节点.那么可以写作:
1 | result=tree.xpath("/a/b/.../x[@attr='value']/...") |
想要在对获得到的所有标签进行遍历时,进一步进行相关搜索,可以通过:
1 | result=tree.xpath("/html/.../") |
获取拿到的标签的属性值:
1 | per_line.xpath("./a/@href") # 获取到a标签中的href值 |
综合来说
/text()获取内容//所有后代/*/不关心孩子节点[n]顺序的筛选[@xxx=]属性的筛选./继续进行搜索/@xxx获取对应的属性值
小技巧:
可以通过抓包工具中获取一个标签的XPATH路径,然后进行微调即可获取同级的内容.
requests
该库的使用中,需要注意在完成一个请求,得到返回值后,要及时关闭响应.
通过使用
responce.close()关闭当前响应常使用的函数内容包括
request.get(url,header,params)以及request.post(url,data,cookies)
进阶使用
1. cookie处理
可以通过session进行请求.(会话)
session的特点是,可以发送一连串的请求且这一连串的请求中的cookie不会丢失.
因此我们的步骤是:
- 登录->得到cookie
- 带着cookie请求后续内容
需要首先创建一个session对象,该对象具有get和post方法
举例:
1 | # 首先创建一个session对象 |
2. 防盗链处理
这里的防盗链的处理以梨视频为例进行分析.
所谓的防盗链只是在请求某个页面时,header中需要存在一个项即Referer,也就是对面的服务器需要知道当前的请求来源,是从哪个页面发出的此请求.
基本步骤
首先进入梨视频主页,随点点击进入一个页面,上方即视频播放页.
通过浏览器抓包工具,查看接收到的
XHR类型的文件可以发现接收到了
JSON数据包,其中包含的即视频的信息.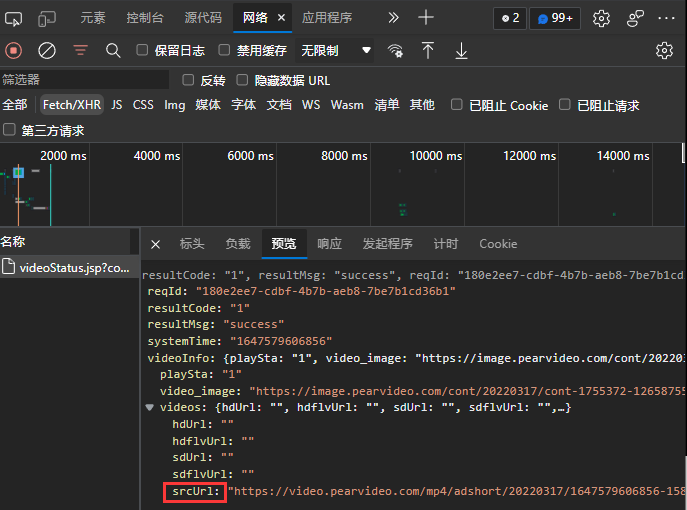
通过其中的
srcURL信息,尝试直接访问视频源,发现网页返回404错误代码.比对网页中嵌入的视频源链接与我们通过JSON包拿到视频源链接,可以发现不同之处

可以发现后者的视频源中,将前者的
164...856部分的数据更换成了cont-1755372因此,只要我们尝试将两者进行转换,即可拿到视频.
对比视频原始所在的页面url,与可播放的url,可以知道,上述更换是将原始界面中的链接部分与后者相结合了.进而我们可以确定爬取思路.
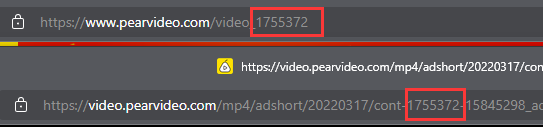
爬取思路
首先根据原url,发送请求抓取json数据包,提取出其中的
systemTime和srcUrl,将
srcUrl部分中的system替换为cont-原url后半部分.向得到的新URL发送请求,拿到视频数据.
代码
其他相关程序:
通过此程序,返回请求时的文件头,
Get选项决定是否添加Referer项内容1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19# -*- codeing = utf-8 -*-
# @Time : 2022/3/18 10:00
# @Author : Baxkiller
# @File : userAgent.py
# @Software : PyCharm
def GetHeaders(URL = "", Get = True):
if not Get:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.56',
}
return headers
else:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.56',
'Referer': URL
}
return headers主爬虫程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84# -*- codeing = utf-8 -*-
# @Time : 2022/3/18 12:51
# @Author : Baxkiller
# @File : LiVideo.py
# @Software : PyCharm
import requests
from userAgent import GetHeaders
from lxml import etree
import time
# 梨视频的视频爬取
# 获取用户给定的视频链接
def Get_InitURL():
initURL = input("请输入想要下载的梨视频页面地址")
backDigit = eval(initURL.split('_')[-1])
return [initURL, backDigit]
# 获取含有视频源的json字典文件,同时解析视频名称
def getJson(videoID, initUrl):
url = f"https://www.pearvideo.com/videoStatus.jsp"
pars = {
"contId": videoID,
"mrd": "0.5174454474260293"
}
# 获取视频的名称
name_resp = requests.get(url = initUrl, headers = GetHeaders(Get = False))
tree = etree.HTML(name_resp.text)
name = tree.xpath(".//h1[@class='video-tt']/text()")[0]
if len(name) == 0:
print("Error:Can't get the name of the Video")
exit()
else:
print("The Video Name is :", name)
# 防止封锁IP
time.sleep(2)
# 获取JSON内容
resp = requests.get(url = url, headers = GetHeaders(initUrl), params = pars)
json = resp.json()
json['name']=name
return json
# 拿到通过json抓取到的视频源地址
# 对拿到的json进行处理,拿到视频源
def get_systime_SrcUrl(json):
systemTime = json['systemTime']
srcUrl = json['videoInfo']['videos']['srcUrl']
return [systemTime, srcUrl]
# 获取视频内容
def askVideo(url):
resp = requests.get(url)
return resp.content
# 将视频内容进行保存
def SaveVideo(Video, path):
try:
f = open(path, mode = "wb")
except Exception:
lt = list('\\/:*?"<>|')
for c in lt:
path=path.replace(c,"_")
f=open(path,mode = "wb")
f.write(Video)
f.close()
if __name__ == "__main__":
[url, subDigit] = Get_InitURL()
json= getJson(subDigit, url)
systime, videoSrc = get_systime_SrcUrl(json)
url = videoSrc.replace(systime, f"cont-{subDigit}")
print("Asking the URL ... ")
VideoContent = askVideo(url)
SaveVideo(VideoContent, f"{json['name']}.mp4")
print("Video Save Finished!")
3. 代理(IP)
通过第三方的服务器去发送请求.
如果对于某个网站的请求发送非常频繁,为了防止IP被封锁,或者说为了解决被封锁掉的IP,可以通过代理进行访问.
一般来说,匿名度为透明的速度较快,而匿名度为高匿的比较慢.
代理的使用只需要在request的方法中添加参数
proxies.而
proxies本身的定义和赋值要区分http和https.
举例:
1 | import requests |
应当注意其中的第四行的两个https与第7行的https应该是对应的.
也就是httpsvshttps
相关知识
web请求解析全过程
服务器渲染
在服务器方将数据与html整合,统一返回给浏览器.
客户端渲染(浏览器方)
如果显示时含有某些内容,而在html的源代码中并没有直接出现该内容,属于客户端渲染.
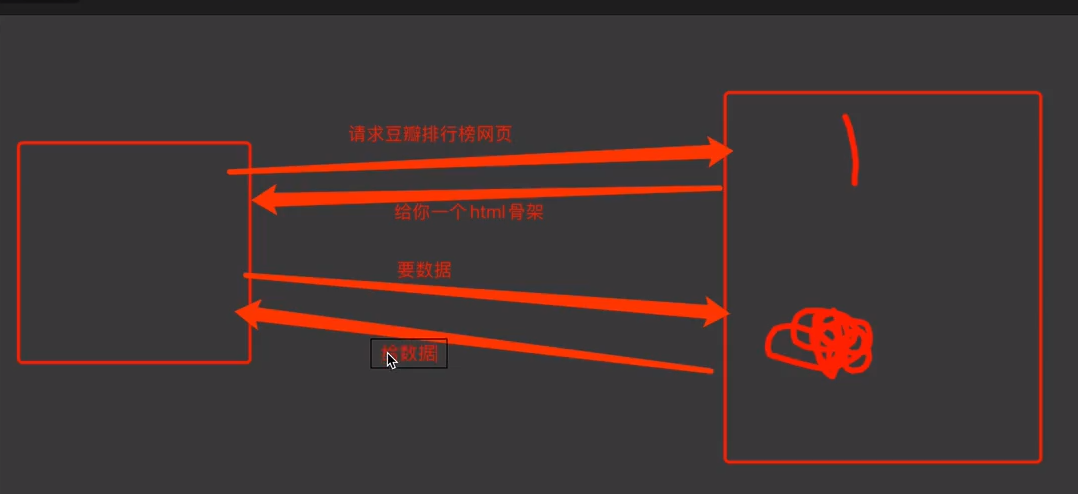
在浏览器方,将html骨架与数据结合在一起.
第一次请求只需要一个html股价,然后其中包含脚本,再次向服务器段请求数据.
第二次的请求可以得到数据,然后将数据与脚本结合,展示出来.
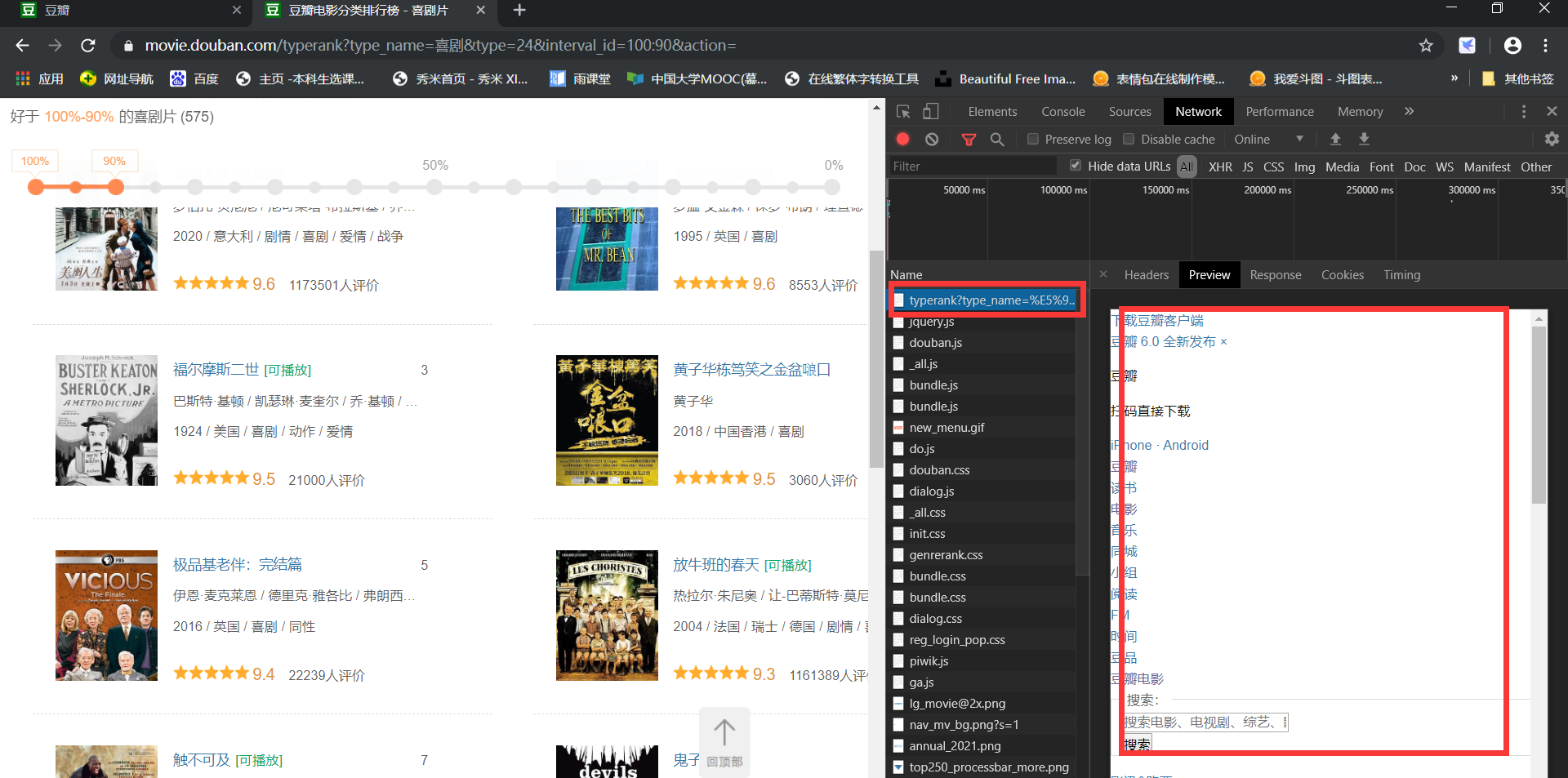
以豆瓣电影中的喜剧片排行榜为例:
第一次请求得到的html框架如下所示:
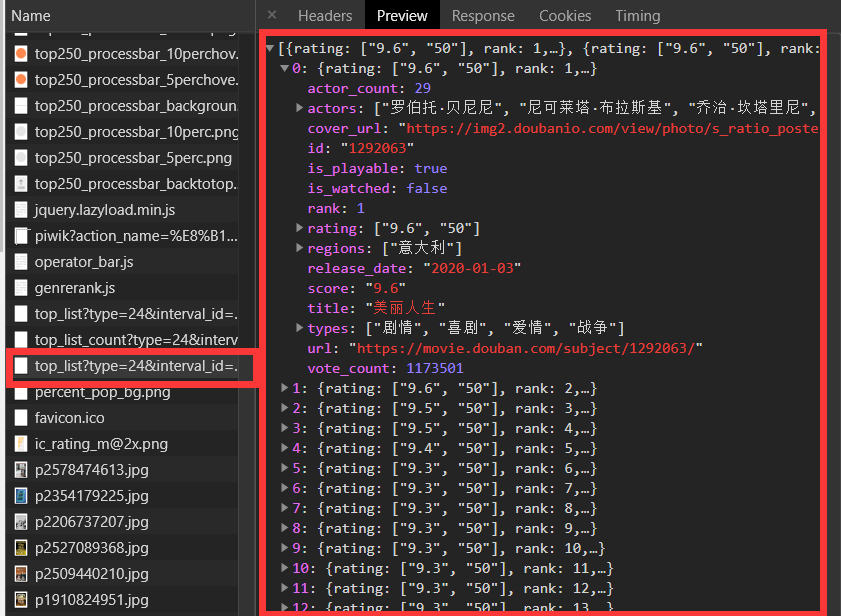
第二次请求得到的数据,通过json文件的形式返回:
第一次请求得到的骨架并不是我们所期望得到的.
http协议
全称超文本传输协议.
http协议的请求和响应都是分为三大块.
请求:
请求行-> 请求方式,请求url地址,协议.
请求头-> 放一些服务器要使用的附加信息
请求体-> 放一些请求参数.
响应:
状态行-> 协议,状态码
响应头-> 放一些客户端要使用的一些附加信息.(密钥/cookie)
响应体-> 服务器返回的真正客户端要用的内容.(HTML,JSON等)
请求头中常见的重要内容:
- user-agent:请求载体的身份信息.
- referer: 防盗链(这次请求是从哪个页面来的.用于反爬虫).
- cookie:本地字符串数据信息(用户登录信息,反爬的token)
响应头中的重要信息:
- cookie: 本地字符串数据信息(用户登录信息,反爬虫的token)
- 各种莫名其妙的字符串(一般都是token字样,防止各种攻击和反爬)
请求方式:
get:显示提交
例如查询.地址栏的内容变动获取到的东西不同,统一属于
GET方式提交.关键点在于,获取内容时传递的参数是通过url进行传递的.比如这里的
query=小妙招:通过f’https://www.sougou.com/query={query}'可以进行参数的传递,也就是在字符串中使用变量的值
给定一个地址url,通过get方式发送请求request.
这里使用到了request库中的get(url),返回值是响应responce
可以通过responce.text获取到网页的源代码.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19import requests
def test():
url = 'https://www.sogou.com/web?query=周杰伦'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.56"
}
resp = requests.get(url, headers = headers)
print(resp) # 返回的是状态码
print("------------------------")
print(resp.text) # 查看的是网页得源代码
if __name__ == "__main__":
test()
print("Finished!")post:隐示提交
请求提交时,发送的数据是通过表单中的数据进行传递的.
对于POST类型的参数传递,通过
requset.post(url=,data=)返回结果通过
responce.json()可以直接得到.想要获得什么数据,就去浏览器抓包工具中找到想要获得的数据.然后查看该数据的标头,得到请求url和请求方法,然后通过爬虫进行爬取.
百度翻译中的单个单词翻译为例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14# post内容发送时,一定要放在字典中进行参数的传递
def translateBaidu(content):
if len(content) <= 1:
print("请重新输入翻译内容:")
return
url = 'https://fanyi.baidu.com/sug'
dat = {
"kw": content
}
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.56"
}
reps = requests.post(url = url, data = dat)
print(reps.json()) # 返回的内容直接处理成json两者的区分
两种方式的区分可以通过浏览器的
F12窗口的抓包工具进行区分.这里举例:
以百度翻译为例.
当输入一个英文单词时,查看F12中的网络选项,在输入之前通过下图按钮清楚请求得到的响应内容.
然后输入,输入完成后查看网络中得到的数据.
这里以输入单词后的单词翻译和提示来讲,可以找到xhr类型的返回值,确定是我们要找的单词的翻译.
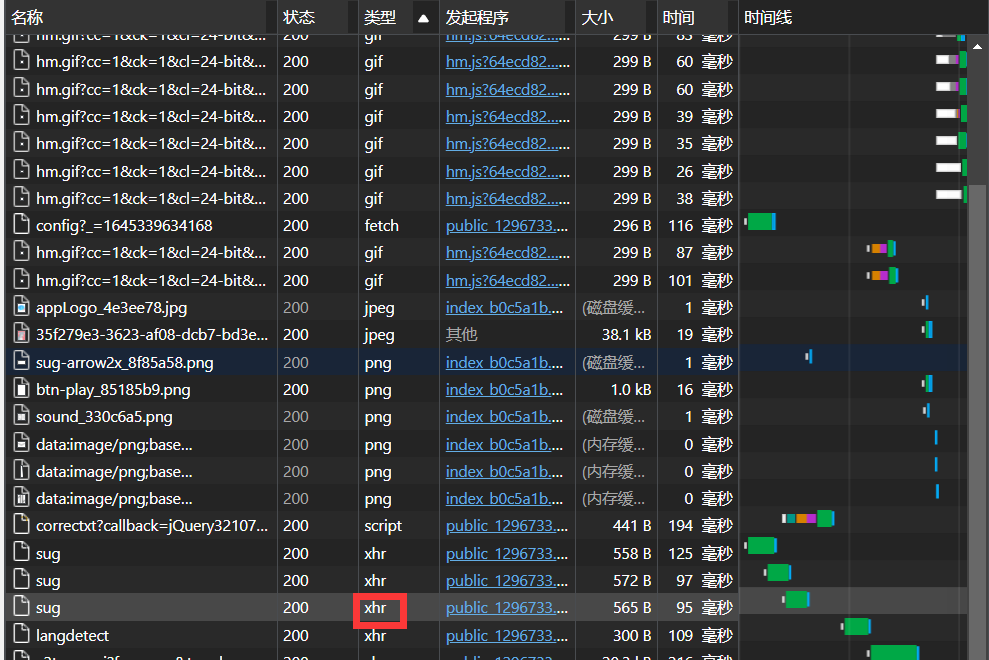
点击内容,查看预览.与目标内容相符

点击标头,查看发送请求的url.
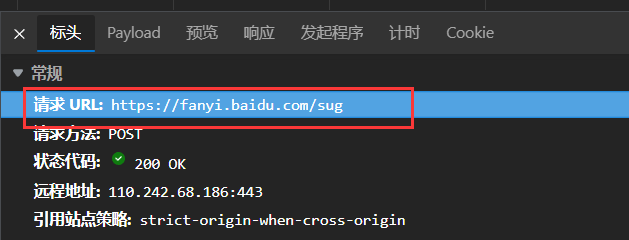
可以发现URL中并没有我们请求的参数.并且在请求方法中已经明确了是
POST.接下来去Payload或者标头页面的最底下找到参数传递: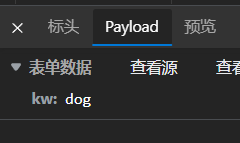
注意字典格式.根据这个格式进行数据传递.
返回值如果要打印,可以直接使用
resp.json()打印获得的xhr类型数据
实战举例
爬取豆瓣某分类的榜单
首先从抓包工具中查找是否具有相关的内容,确定渲染类型.
根据下图可以发现,该榜单内容属于浏览器端渲染.因此可以直接截取到相关的json文件.
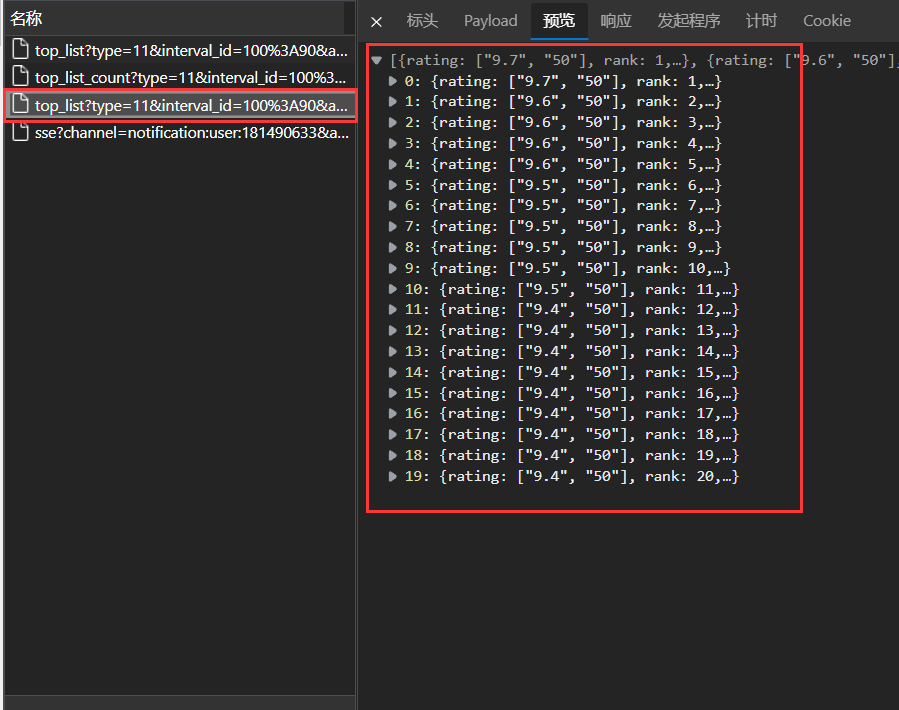
其次,根据上图,查看对应文件的标头,得知请求方法.根据下图来看,可以知道是
GET类型.因此可以直接通过向对应链接使用request.get(url=url,headers=headers)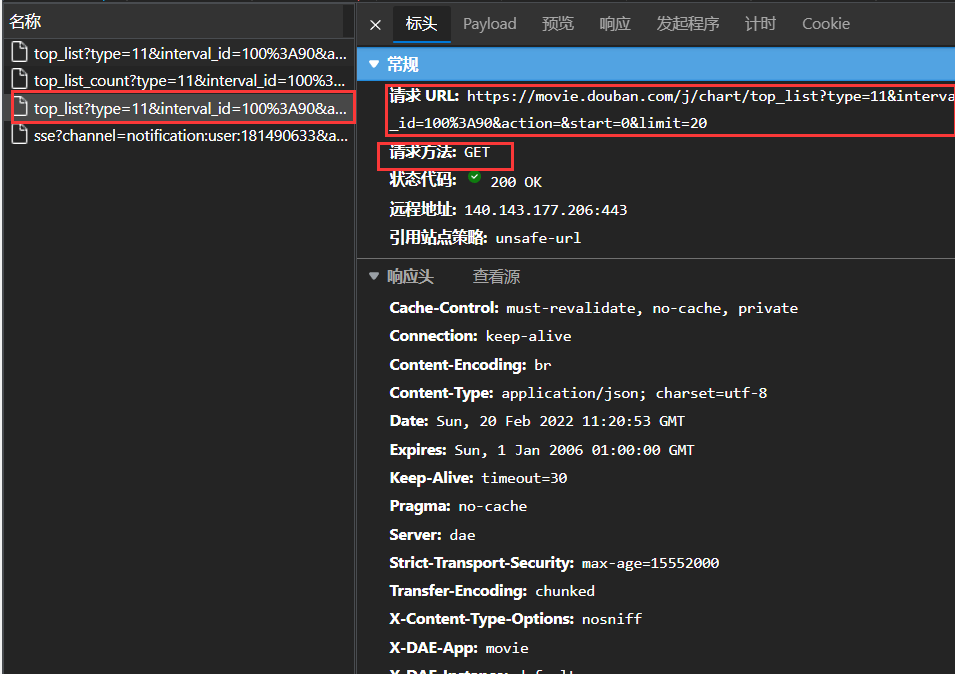
查看是否存在参数的传递
查看对应的
Payload,可以发现这里存在着参数传递.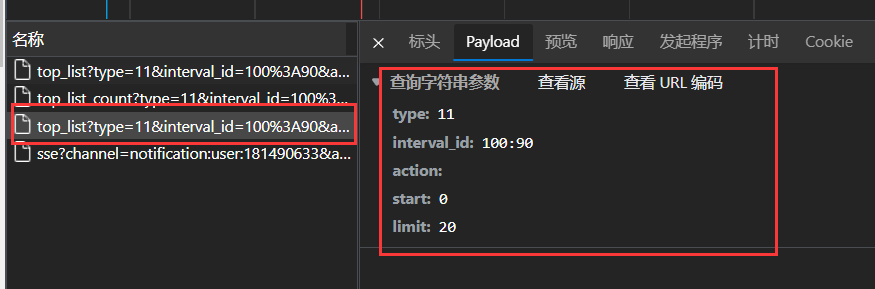
综合
综上来看,确定要获取内容形式如下:
以
https://movie.douban.com/j/chart/top_list作为基础链接,问号后的内容实际上是参数的传递.因此可以确定我们要使用的函数为:request.get(url=baseurl,param=para,headers=headers)其中的para以及headers为参数字典.
以上图为例,其参数字典如下:
1
2
3
4
5
6
7para = {
"type": "11",
"interval_id": "100:90",
"action": "",
"start": 0,
"limit": 20,
}结果
发送请求后得到的结果,通过
resp.json()直接提取返回的内容值.提取到的是字典类型的数据dict.这里将请求结果存储在文件中,但是在存储之前要注意将原本的返回结果中的单引号
'更换为json文件常使用的双引号"代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import requests
def GetRank():
url = "https://movie.douban.com/j/chart/top_list" # 原url链接问号后的内容为参数
para = {
"type": "11",
"interval_id": "100:90",
"action": "",
"start": 0,
"limit": 20,
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.56',
}
# 通过url与para的结合 可以生成我们想要的url
resp = requests.get(url = url, params = para, headers = headers)
resp.close()
return resp.json()
if __name__ == "__main__":
fhandle = open("rangeOfPlot.json", mode = "w", encoding = 'utf-8')
res = Douban.GetRank()
strRes = str(res)
strRes = strRes.replace(__old = '\'', __new = '\"')
fhandle.write(str(res))
print("Finished!")
数据解析
适用条件:对于服务器渲染方式的网页,通过数据解析直接获取到网页的数据内容.
这里介绍三种方 式:RE(正则表达式),BS4(BeautifulSoup) ,XPATH(应用范围最广)
RE
详情可以查看上面提到的”re正则表达式”模块的介绍.
测试正则表达式的在线网站工具:在线正则表达式测试
(虽然之前已经给出了匹配符号的规则等等,这里还是再给一遍)
常用元字符(具有固定含义的特殊符号)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17. 匹配除换行符以外的任意字符
\w 匹配字母数字下划线
\s 匹配任意的空白符(例如换行,空格)
\d 匹配数字
\n 匹配一个换行符
\t 匹配一个制表符
^ 匹配字符串的开始
$ 匹配字符串的结尾
\W 匹配非字母数字下划线
\D 匹配非数字
\S 匹配非空白字符
a|b 匹配a或b
() 匹配括号内的表达式,也表示一个组
[...] 匹配字符组中的字符
[^...] 匹配非字符组中的字符量词:控制前面的元字符出现的次数
1
2
3
4
5
6* 重复0次或者无数次
+ 重复1次或者无数次
? 重复0次或者1次
{n} 重复n次
{n,} 重复n次或者更多次
{n,m} 重复n到m次贪婪匹配和惰性匹配
1
2.* 贪婪匹配
.*? 惰性匹配其中爬虫中常用的是**惰性匹配.**意义为:令前面这个
*少一点,尽可能让这个*匹配到少一点东西.原理在于,首先进行贪婪匹配,找到最远的符合条件的尾部,然后再从尾部向前找到尾部最后一次出现的结果.
举例:
原字符串:
玩儿吃鸡游戏,晚上一起玩游戏.干啥呢?打游戏啊符合正则表达式:
玩儿.*游戏的字符串包括:- 玩儿吃鸡游戏
- 玩儿吃鸡游戏,晚上一起玩游戏
- 玩儿吃鸡游戏,晚上一起玩游戏.干啥呢?打游戏
通过
玩儿.*?游戏,那么匹配的结果为1.如果
玩儿.*游戏,那么匹配结果为3.
其他内容
对于编码问题
encode指代的是将普通字符串转化为机器可识别的bytes
decode指代的是将bytes转化成字符串
因此对于Python3来说,str类型的数据不存在decode方法,只能进行encode.
如果在爬取网站时,网站的内容编码方式不是常见的
utf-8,而是其他编码方式,例如gbk或者gb2312对于
requests库,通过发送请求后的返回值设定1
2resp=requests.get(url=url)
resp.encoding='gbk' # 或resp.encoding='gb2312'对于
urllib1
2resp=urllib.request.urlopen(request)
html=resp.read().decode('gbk')
针对网站的防火墙问题
报错:
Max retries exceeded with url:(Caused by SSLError("bad handshake:Error([('SSL routines','tls_process_server_certificate','certificate verify failed')])"))通过增加参数:
1
resp=requests.get(url=url,verify=False)
数据保存
对于通过
requests库获取到的内容,如果要以二进制的形式进行保存(例如我们需要对下载到的图片进行保存)通过获取
1
2resp=requests.get(url)
resp.content ##这就是我们要获得到的二进制文件